value
0 1
6000 4000 [1] 0.4May 19, 2025
M&Ms has a precise distribution of colors that it produces in its factories
M&Ms are sorted into bags in factories in a fairly random process
Get in groups of 2. Each group will have 4-5 bags of M&Ms.
Each bag represents a Sample from the full Population of M&Ms
Keep the contents of each bag separate, and do not eat (yet!)
Open up your first bag of M&Ms: calculate the proportion of the M&Ms that are blue. Write this down.
Do the same as above for the rest of your bags (you should have 4-5 estimates). Keep these estimates on hand.
Calculate the mean of your estimates.
Come to the board to add the data you collected to the full class histogram
What is your best guess about the percentage of all M&Ms that are blue?
When you are done, discuss the following with partner:
What is the histogram/distribution on the board showing?
Why do some bags of M&Ms have proportions of blues that are higher and lower than the number you gave above?
Based on the histogram on the board, what is your answer to the question of what percentage of all milk chocolate M&Ms are blue? Why do you give that answer?
We completed this task many times
This produced a Sampling Distribution of our Estimates
There is a distribution of estimates because of Sampling Variability
We do not repeat sampling processes many times
These concepts about sampling and sampling variability are foundational ideas for statistical inference that we are going to keep building on
Big idea: when we observe a sample of data, we are looking at one draw from a distribution of possible draws (or worlds)
Prior classes focused on data visualization and summary
Now, we turn to inference: the kinds of conclusions we can and want to draw from our data
In data analysis, we are usually interested in saying something about a Target Population.
What proportion of adult Russians support the war in Ukraine?
How many US college students check social media during their classes?
In many instances, we have a Sample
We cannot talk to every Russian
We cannot talk to all college students
The Parameter: this is the value of a calculation for the entire target population
The Statistic: this is what we calculate on our sample
Inference is the act of “making a guess” about some unknown.
Statistical inference: making a good guess about a population from a sample
Causal inference: did X cause Y? [topic for later classes]
Question: What proportion of adult (18+) Russian citizens support the war in Ukraine?
What is the Population of interest?
What is the Parameter of interest?
Our population has 4000 supporters, and 6000 non-supporters
What is the population parameter?
This is the Population: in real research, we do not have this information!
What does it mean to say that this is a random sample?
All units in the population have an equal Probability of being selected
When I calculate the mean in the sample, what am I calculating?
Our Estimate of the population parameter
# Gather 1,000 estimates
sims <- 1000
# Store the sample means in this object called "ests"
ests <- rep(NA, sims)
# For loops allow us to run the same procedure many times
for(i in 1:sims){
sample <- slice_sample(pop, n= 20)
# store mean in our vector of estimates
ests[i] <- mean(sample$value)
}
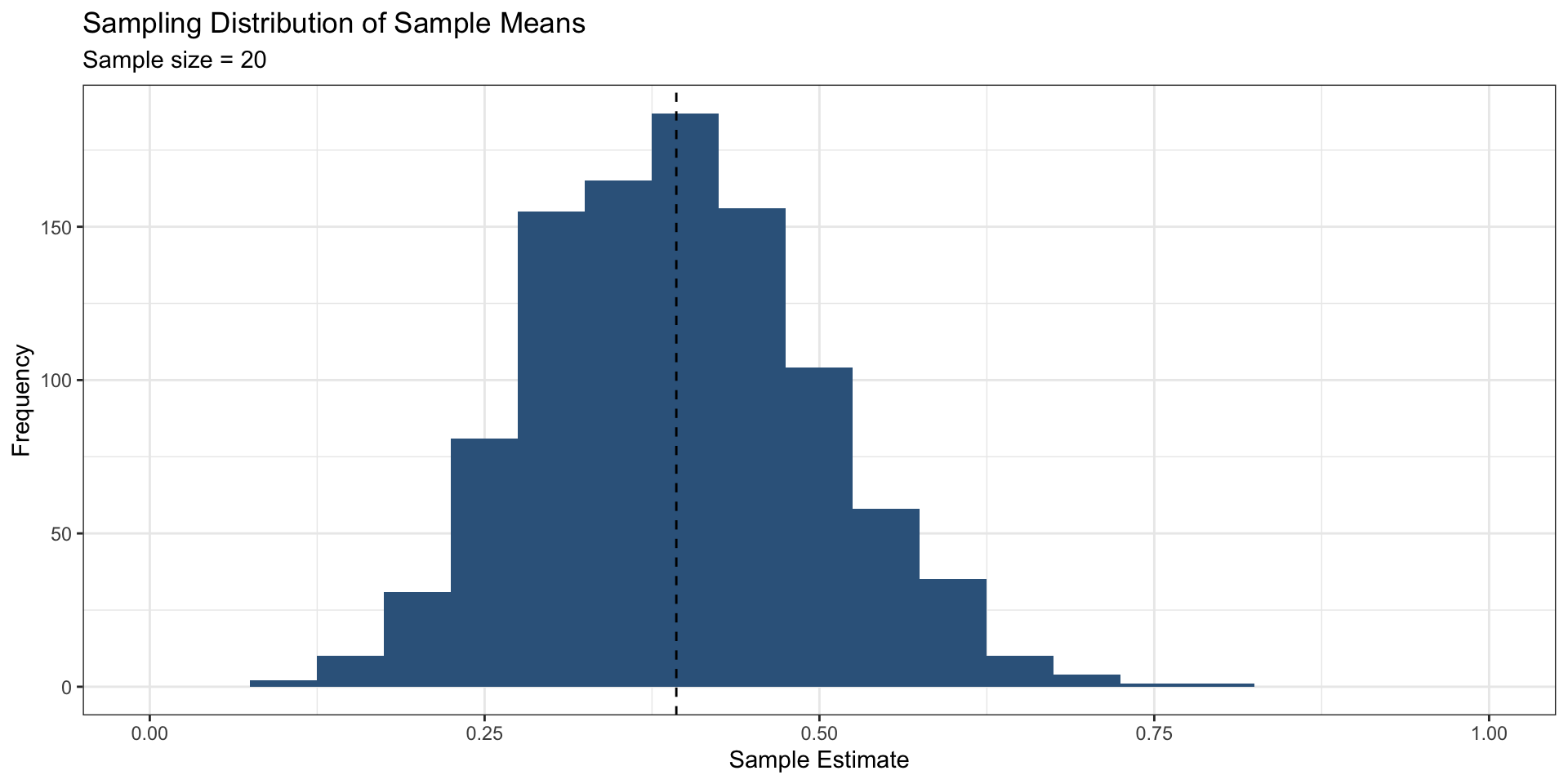
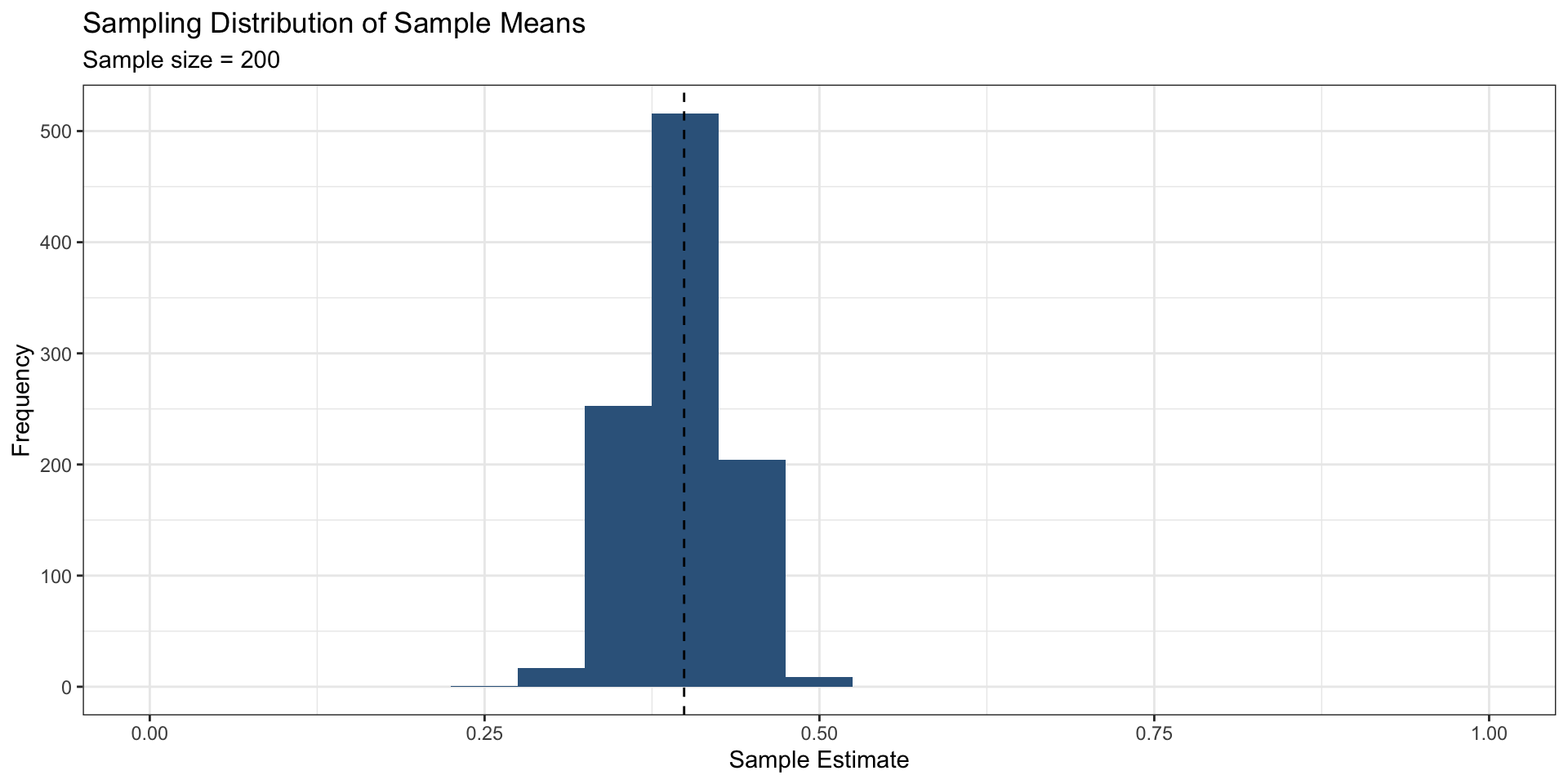
ests <- as_tibble(ests)Or, what should the mean of ests be?
The mean of ests is almost exactly the same as the population mean (which we know because we set it)
This means that our procedure (random sampling + taking the mean) for estimating the population mean is unbiased
An unbiased procedure does not guarantee that we will get the “right” answer every time
This is due to random chance, or sampling variability
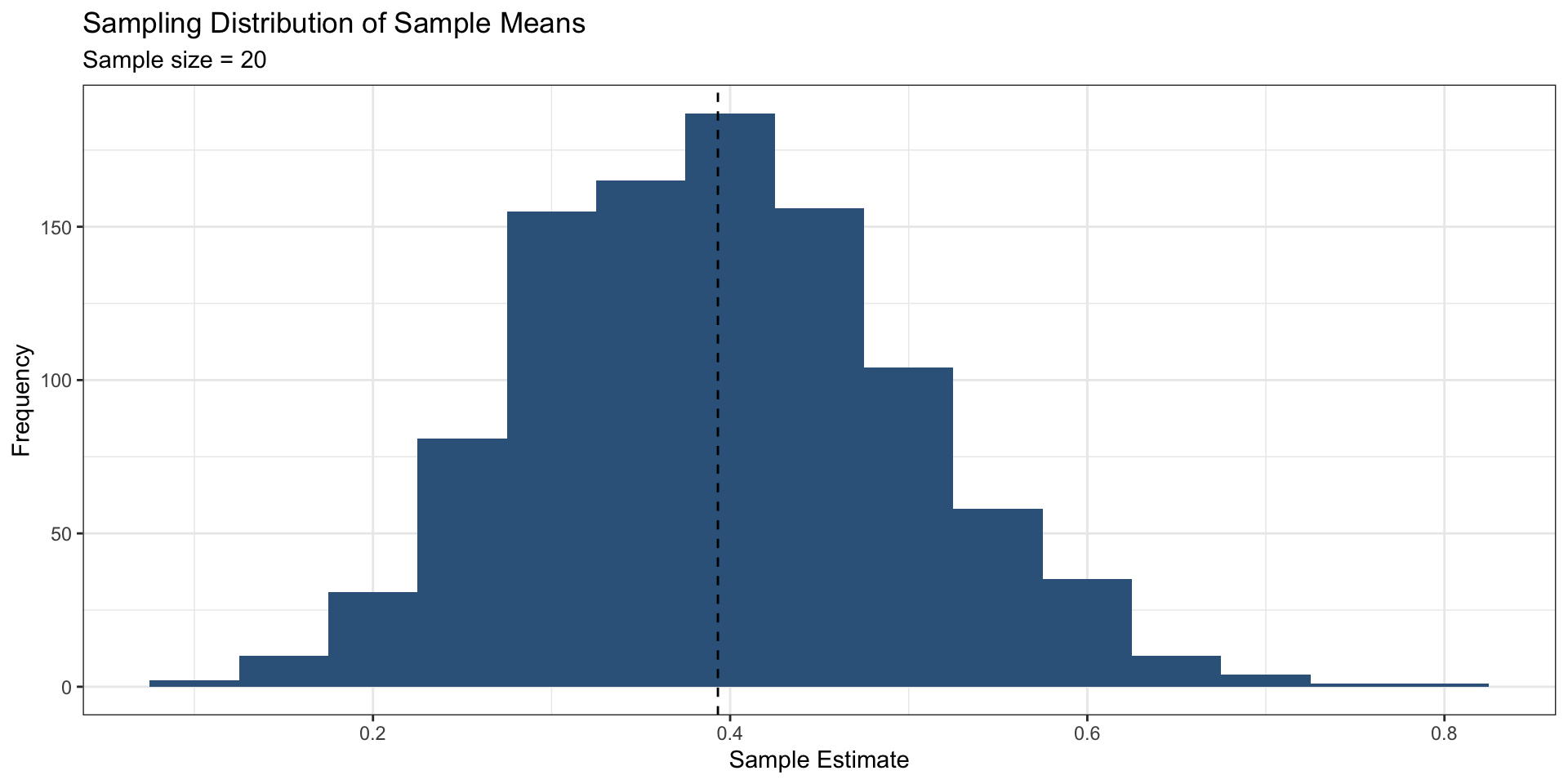
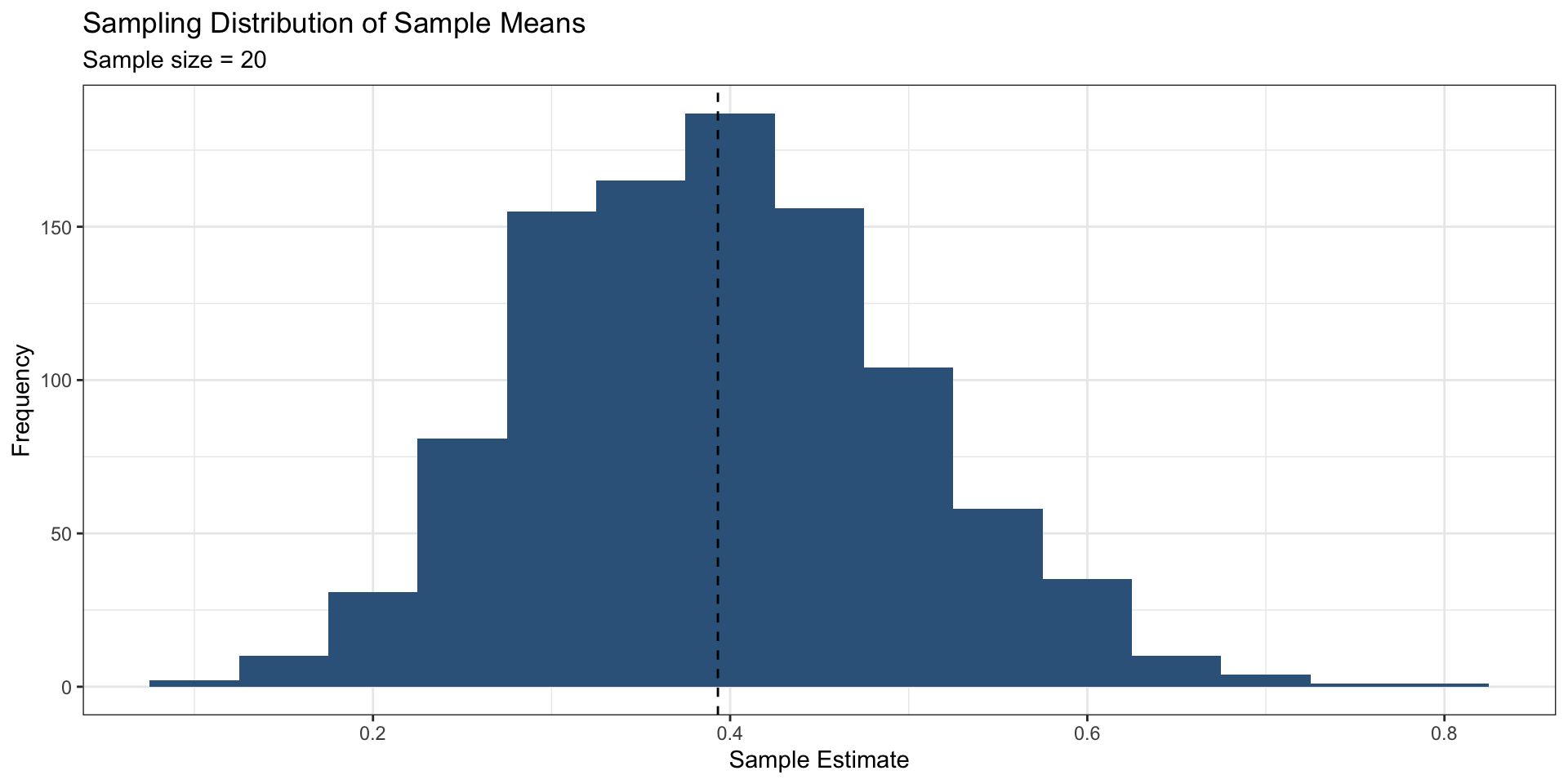
Standard deviation of the sampling distribution
Characterizes the spread of the sampling distribution
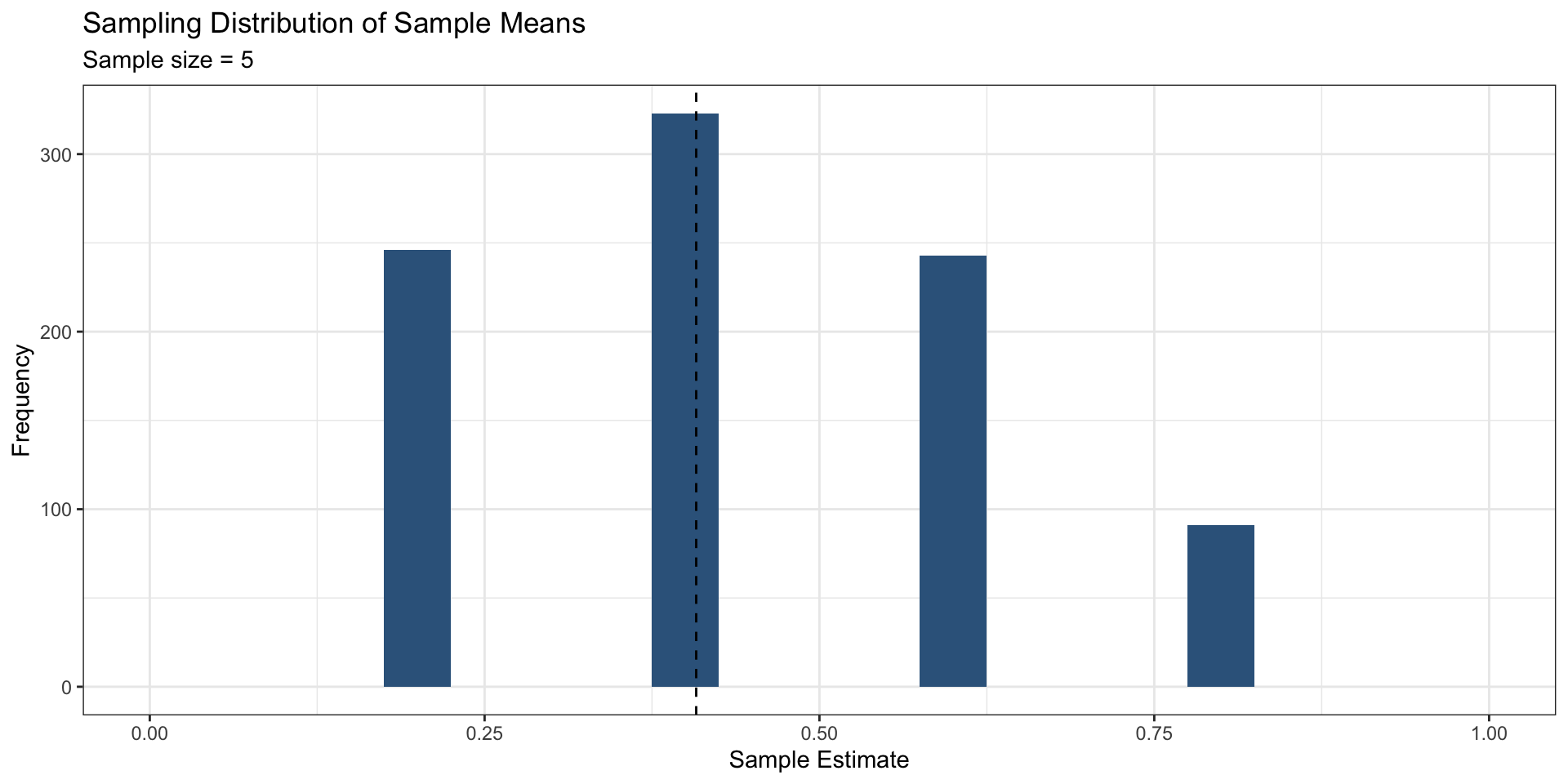
Repeat the simulations conducted above:
For each: Are these biased or unbiased procedures?
Visualize the sampling distributions using a histogram: how are they different?
Calculate the standard errors: how are they different?
Discuss with partner: Why are the sampling distributions and standard errors different?
As sample size gets bigger . . .
The spread of the sampling distribution gets narrower
The shape of the sampling distributions becomes more normally distributed
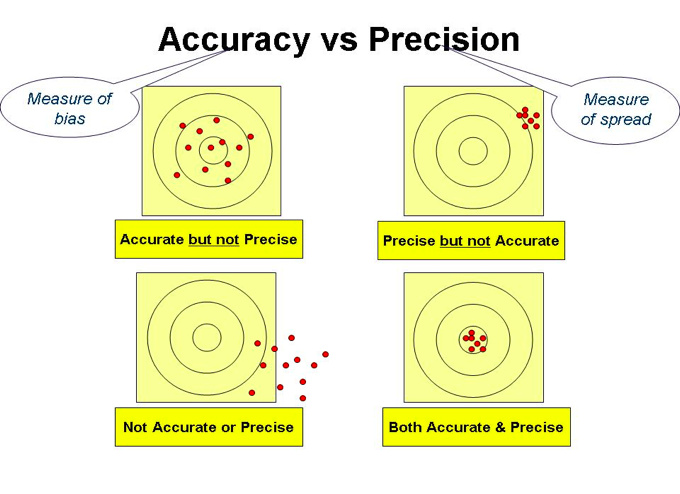
Precision refers to variability: procedures with less sampling variability will be more precise
A development organization is trying to build evidence demonstrating the impact of their programming on political participation. The program has hundreds of participants. Five program participants volunteered to provide information on their political participation and each reports that they participate much more after they were in the program. The development organization concludes that the program had the intended impact of increasing political participation.
A development organization is trying to build evidence demonstrating the impact of their programming on political participation. The program has hundreds of participants. Five program participants were randomly selected to provide information on their political participation and each reports that they participate much more after they were in the program. The development organization concludes that the program had the intended impact of increasing political participation.
A polling firm is trying to estimate the proportion of likely voters that will vote for President Biden. They draw a random sample of 1000 adult Americans and ask them whether they intend to vote for Biden. From this, they calculate the proportion who intend to vote for Biden.
In 2016, polling firms using random sampling tried to estimate the proportion of adult Americans who would vote for Trump. In surveys in America, the response rate is very low (~10 percent) and people without a college education are less likely to respond to surveys than are other Americans.
Researchers are interested in studying the political attitudes of ex-combatants in a civil war. They have a limited budget and are debating the best research design. In option A, they use random sampling, which is very expensive given the target population (they have to enumerate ex-combatants and then track them down, which is resource intensive). This would allow them to survey 20 ex-combatants given the budget. In option B, they use snowball sampling, where ex-combatants introduce the researchers to other ex-combatants that they know. This is much cheaper, and would result in a sample size of 250.
Sometimes, a little bit of bias is OK, if it buys us a lot more precision [small bias + high precision]
An unbiased study with very low precision is not informative (as we will discover more in future classes)
But this depends on how much bias there is: high bias + high precision is not a good outcome.